Wo liegen Grenzen des Machine Learning?
Wo liegen Grenzen des Machine Learning?
Wir möchten uns nun noch mit zwei grundlegenden methodischen Problem des Machine Learning beschäftigen: Overfitting und Underfitting.
💭 Denken Sie kurz nach. Was könnte mit diesen Begriffen gemeint sein?
Behalten Sie für die Beantwortung der Frage im Hinterkopf, dass künstliche neuronale Netze auf Basis eines Datensatzes (sog. Trainingsdaten) lernen. Letztendlich sollen sie aber neue Fälle zuverlässig klassifizieren.
Overfitting und Underfitting
Im Bild werden der Trainingsdatensatz (Datenpunkte) und das gelernte Modell (Linie) dargestellt.
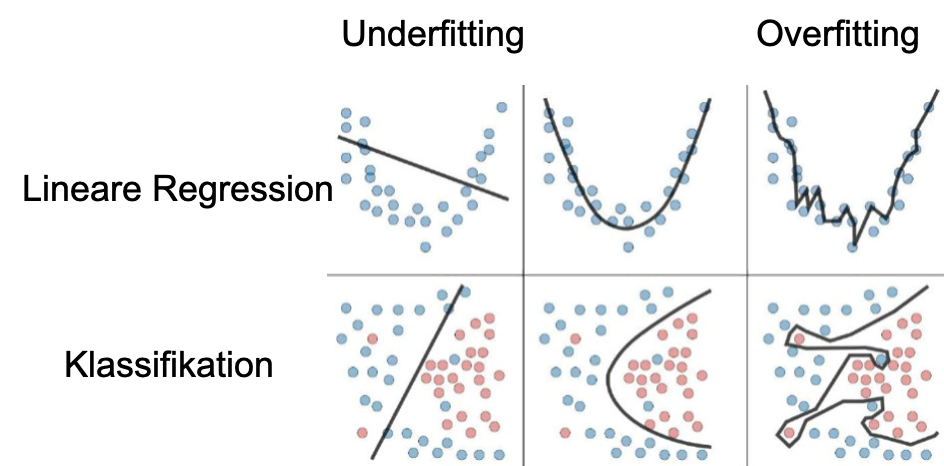
Overfitting (oder Überanpassung) passiert, wenn ein Modell übermäßig an die Trainingsdaten angepasst ist (siehe Abbildung 1, rechts) und eine Übertragung des Modells auf eine Grundgesamtheit (Generalisierung) nicht mehr möglich ist. Der Fehler im Trainingsdatensatz ist dann sehr gering, testet man das Modell allerdings mit neuen Daten, ist der Fehler relativ hoch (siehe Abbildung 2).
Beim Underfitting beschreibt das Modell den realen Sachverhalt generell nicht gut oder nur sehr ungenau (siehe Abbildung 1, links). Es gibt also sowohl im Trainingsdatensatz als auch bei neuen Daten einen relativ großen Fehler (siehe Abbildung 2).
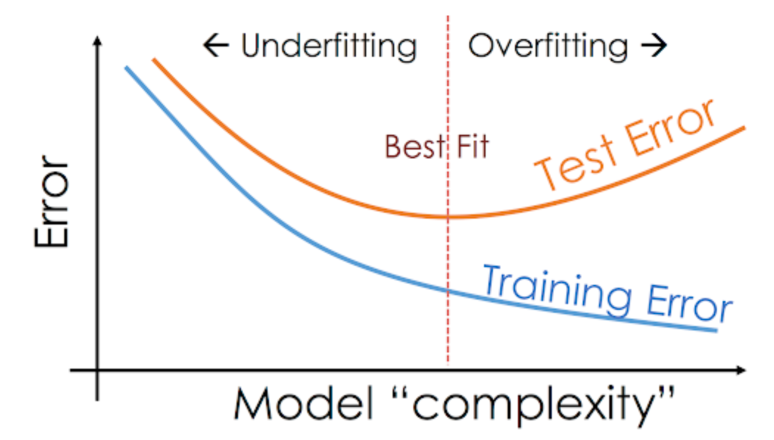
Ziel ist es einen möglichst guten Kompromiss zwischen Anpassungsgenauigkeit und Generalisierbarkeit zu finden (siehe Abbildung 2, Best Fit)
Overfitting im Mammografiebeispiel
Studie zum Thema
Artificial neural networks in mammography: application to decision making in the diagnosis of breast cancer (Wu et al., 1993)
Wu und Kollegen führten 1993 eine Studie durch, die unserem Beispiel sehr nahe kommt. Die Autoren untersuchten den potenziellen Nutzen von künstlichen neuronalen Netzen als Entscheidungshilfe für Radiologen bei der Analyse von Mammographiedaten.
Sie nutzten neuronale Netze mit drei Verarbeitungsschichten und einen Backpropagation Algorithmus zur Interpretation von Mammographien auf Basis von Features, die von erfahrenen Radiologen aus Mammographien ausgewählt wurden.
Ein Netz mit 43 Features, war bei der Klassifikation von gutartigen und bösartigen Tumoren gut geeignet und erreichte einen Wert von 95 % richtig klassifizierter Fälle – für eindeutige Fälle.
Bei klinischen Fällen war die Leistung eines neuronalen Netzes anhand von 14 vom Radiologen extrahierten Merkmalen zur Unterscheidung zwischen gutartigen und bösartigen Tumoren höher als die durchschnittliche Leistung von behandelnden und niedergelassenen Radiologen.
Die Studie kann hier abgerufen werden.
Abschluss
Das war bereits Ihr zweites Trainingsmodul. Wir haben uns vor allem mit den methodischen Grundlagen von künstlicher Intelligenz beschäftigt: dem Machine Learning und den künstlichen neuronalen Netzen. Ich hoffe, ich konnte Ihnen diese Grundideen etwas näher bringen. Tatsächlich bin ich der festen Überzeugung, dass Sie als statistisch gut ausgebildete Psychologiestudierende(r) alle nötigen statistischen Kenntnisse bereits mitbringen. So ist es nur ein kleiner Schritt von fortgeschrittener Inferenzstatistik zum Machine Learning. In den nächsten Einheiten beschäftigen wir uns mit den Anwendungsmöglichkeiten von KI und auch damit, welche ethischen und rechtlichen Bedenken es gibt.
Ich freue mich, wenn Sie auch am nächsten Modul teilnehmen.
Quellen
- Ng, A. (2011). Machine Learning [Online Course]. Stanford University. https://www.coursera.org/learn/machine-learning/home/welcome
- Reinhart, J., & Greiner, C. (2019). Whitepaper Künstliche Intelligenz: Grundlagen, Anwendungsfelder und Umsetzungsstrategien.
- Russell, S. J., & Norvig, P. (2012). Künstliche Intelligenz: Ein moderner Ansatz (3rd ed.). Pearson.
- Smilkov, D., & Carter, S. (2020, April 17). Tensorflow Playground. https://playground.tensorflow.org/
- Wu, Y., Giger, M. L., Doi, K., Vyborny, C. J., Schmidt, R. A., & Metz, C. E. (1993). Artificial Neural Networks in Mammography: Application to Decision Making in the Diagnosis of Breast Cancer. Radiology, 187(1), 81-87. https://doi.org/10.1148/radiology.187.1.8451441
P.S. Hier noch die Lösung für das angesprochene “Dog-Or-Muffin”-Problem.